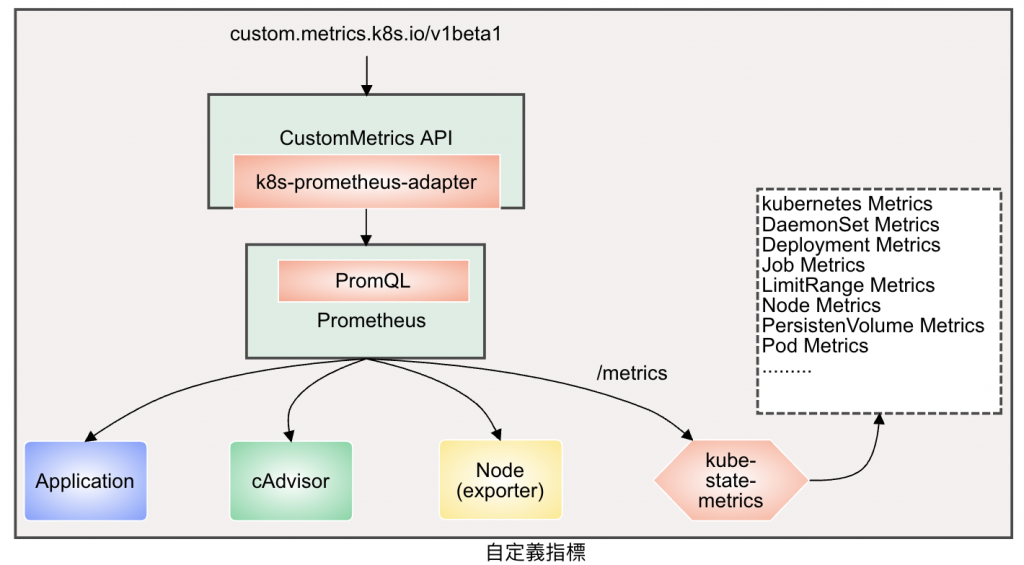
自定義指標API允許請求任意指標, 目的是提供用戶和K8s組建一個可以依賴的穩定的API, 要實現指標API需要相應的後端監視系統, Prometheus 是第一個開發相應適配器的監控系統, K8s也由k8s-prometheus-adapter提供了適用Prometheus的Kubernetes Custom Metrics Adapter, 目前由github託管。
Prometheus是一個開源的服務監控系統和時序資料庫, 它提供通用的資料模型和便捷的資料搜集、儲存、查詢接口;Prometheus 服務器會定期從監控目標或者服務發現自動配置的目標中拉取數據, 如果新的數據超過預設的Memory容量時, 數據會被儲存到持久化設備中。
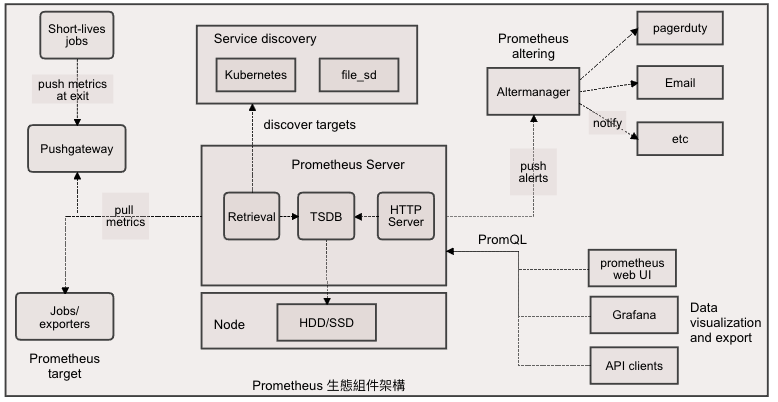
每個被監控的組件都可以透過專用的exporter提供輸出數據的接口, 並等待Prometheus服務器定時來抓取數據。如果有設定警示規則, 則在Prometheus抓取資料後會依照警示規則進行檢查, 一旦滿足警示條件就會發送警示內容到Altermanager。被監控的目標有推送訊息的需求時可以部署Pushgateway來接收推送與暫存訊息。
Prometheus支援監控幾個k8s上的非核心指標數據, 項目如下:
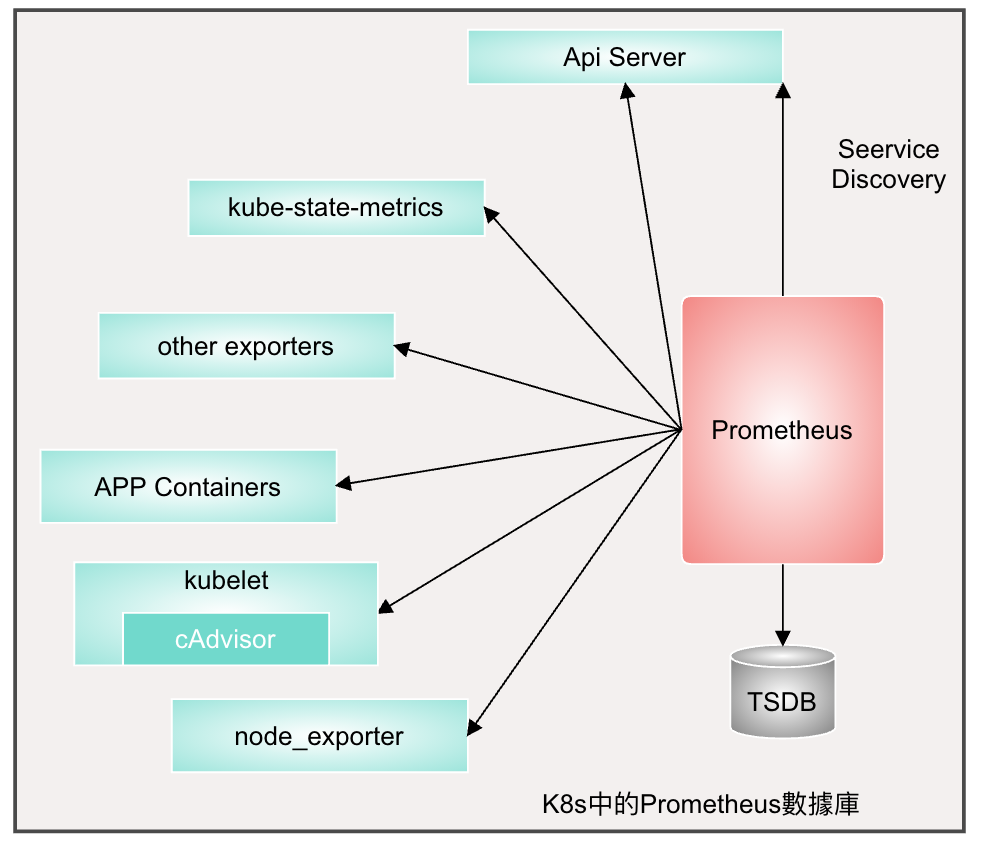
Prometheus 可以直接把k8s API Server作為服務發現系統使用進而動態發現和監控cluster中所有可被監控的對象, 但是Pod需要添加幾個註解才能被Prometheus自動發現和抓取內建指標數據。
Pod須添加的註解:
boolean, 用來標示是否需要被採集指標數據Prometheus 今天先理解概念和運作方式, google了幾個實作的部分都是和HELM一起搭配的, 所以預計等到Helm讀完再一併安裝起來玩看看。


 iThome鐵人賽
iThome鐵人賽